Dataframes
Dataframes are a great way to display and edit data in a tabular format. Working with Pandas DataFrames and other tabular data structures is key to data science workflows. If developers and data scientists want to display this data in Streamlit, they have multiple options: st.dataframe and st.data_editor. If you want to solely display data in a table-like UI, st.dataframe is the way to go. If you want to interactively edit data, use st.data_editor. We explore the use cases and advantages of each option in the following sections.
Display dataframes with st.dataframe
Streamlit can display dataframes in a table-like UI via st.dataframe :
import streamlit as st
import pandas as pd
df = pd.DataFrame(
[
{"command": "st.selectbox", "rating": 4, "is_widget": True},
{"command": "st.balloons", "rating": 5, "is_widget": False},
{"command": "st.time_input", "rating": 3, "is_widget": True},
]
)
st.dataframe(df, use_container_width=True)
Additional UI features
st.dataframe also provides some additional functionality by using glide-data-grid under the hood:
- Column sorting: sort columns by clicking on their headers.
- Column resizing: resize columns by dragging and dropping column header borders.
- Table resizing: resize tables by dragging and dropping the bottom right corner.
- Search: search through data by clicking a table, using hotkeys (
⌘ Cmd + ForCtrl + F) to bring up the search bar, and using the search bar to filter data. - Copy to clipboard: select one or multiple cells, copy them to the clipboard and paste them into your favorite spreadsheet software.
Try out all the UI features using the embedded app from the prior section.
In addition to Pandas DataFrames, st.dataframe also supports other common Python types, e.g., list, dict, or numpy array. It also supports Snowpark and PySpark DataFrames, which allow you to lazily evaluate and pull data from databases. This can be useful for working with large datasets.
Edit data with st.data_editor
Streamlit supports editable dataframes via the st.data_editor command. Check out its API in st.data_editor. It shows the dataframe in a table, similar to st.dataframe. But in contrast to st.dataframe, this table isn't static! The user can click on cells and edit them. The edited data is then returned on the Python side. Here's an example:
df = pd.DataFrame(
[
{"command": "st.selectbox", "rating": 4, "is_widget": True},
{"command": "st.balloons", "rating": 5, "is_widget": False},
{"command": "st.time_input", "rating": 3, "is_widget": True},
]
)
df = load_data()
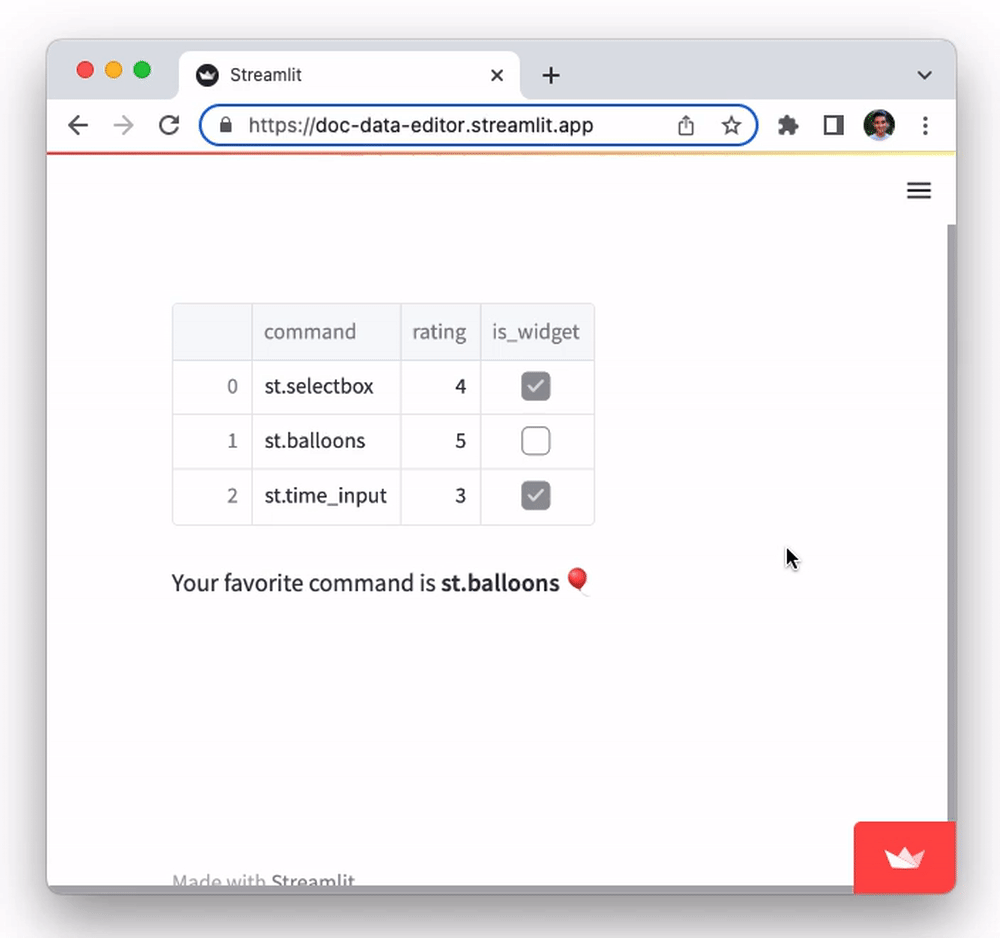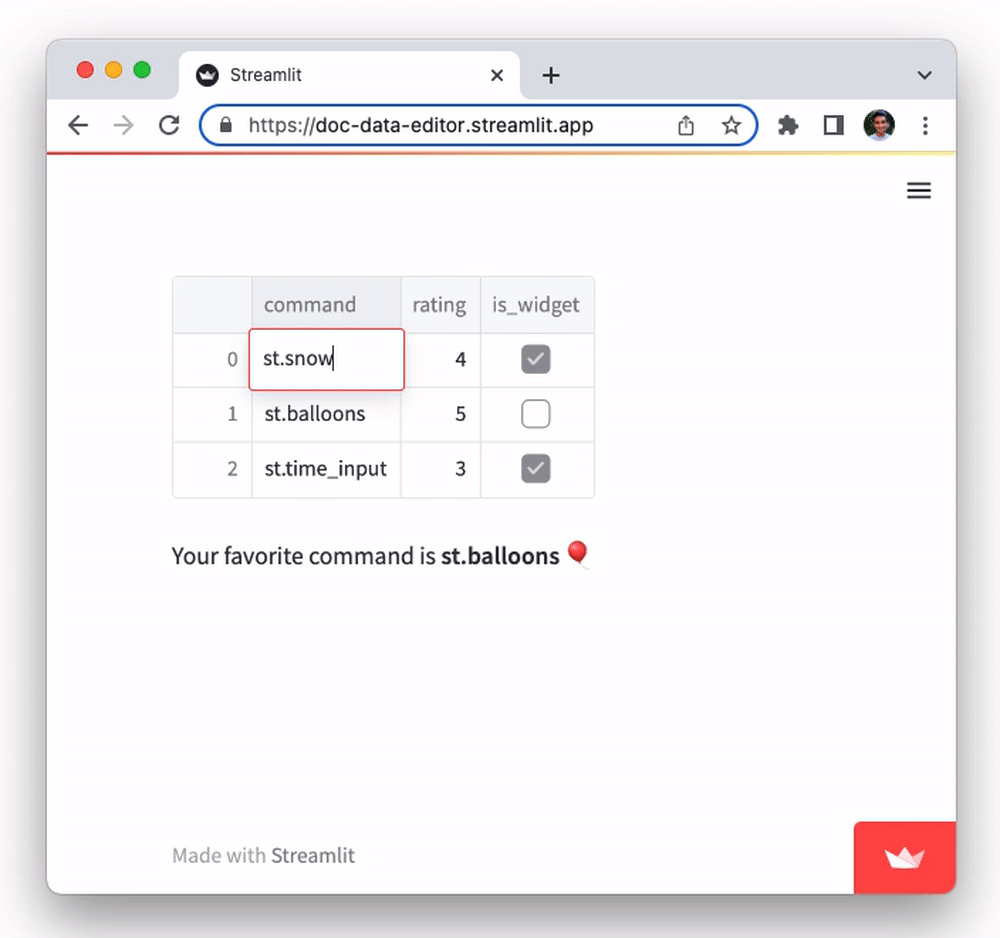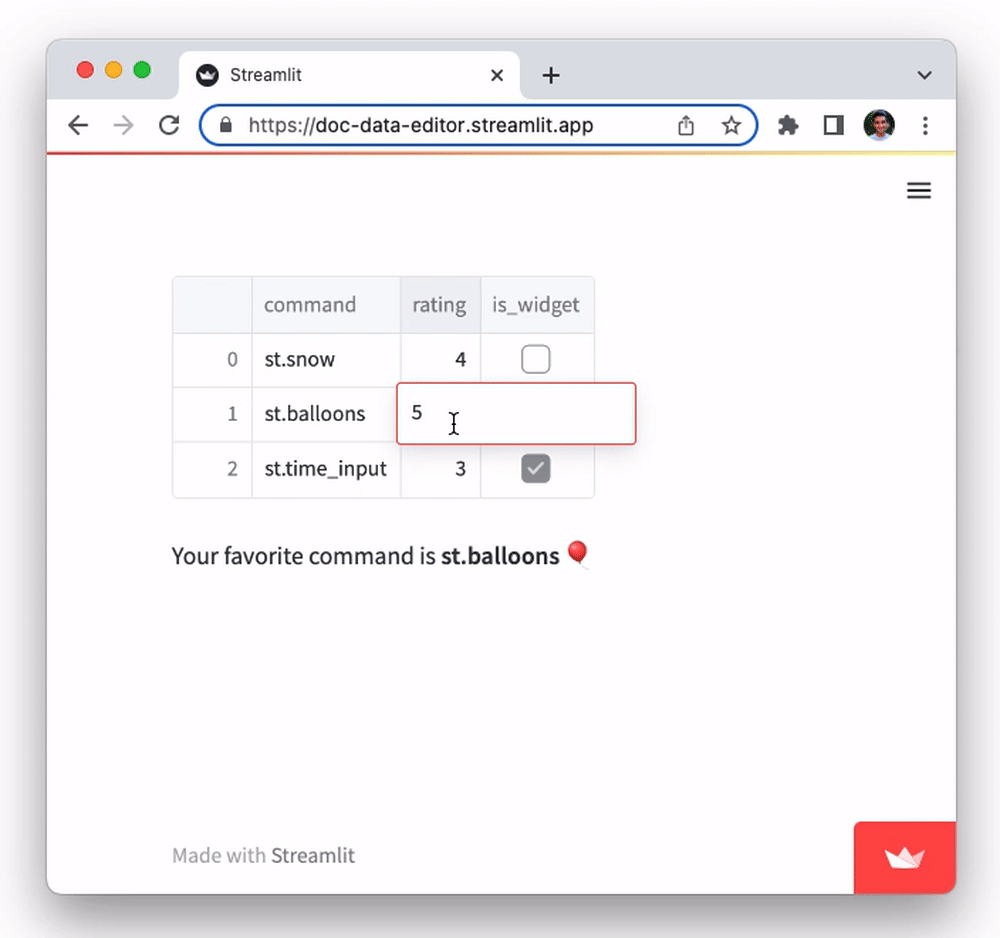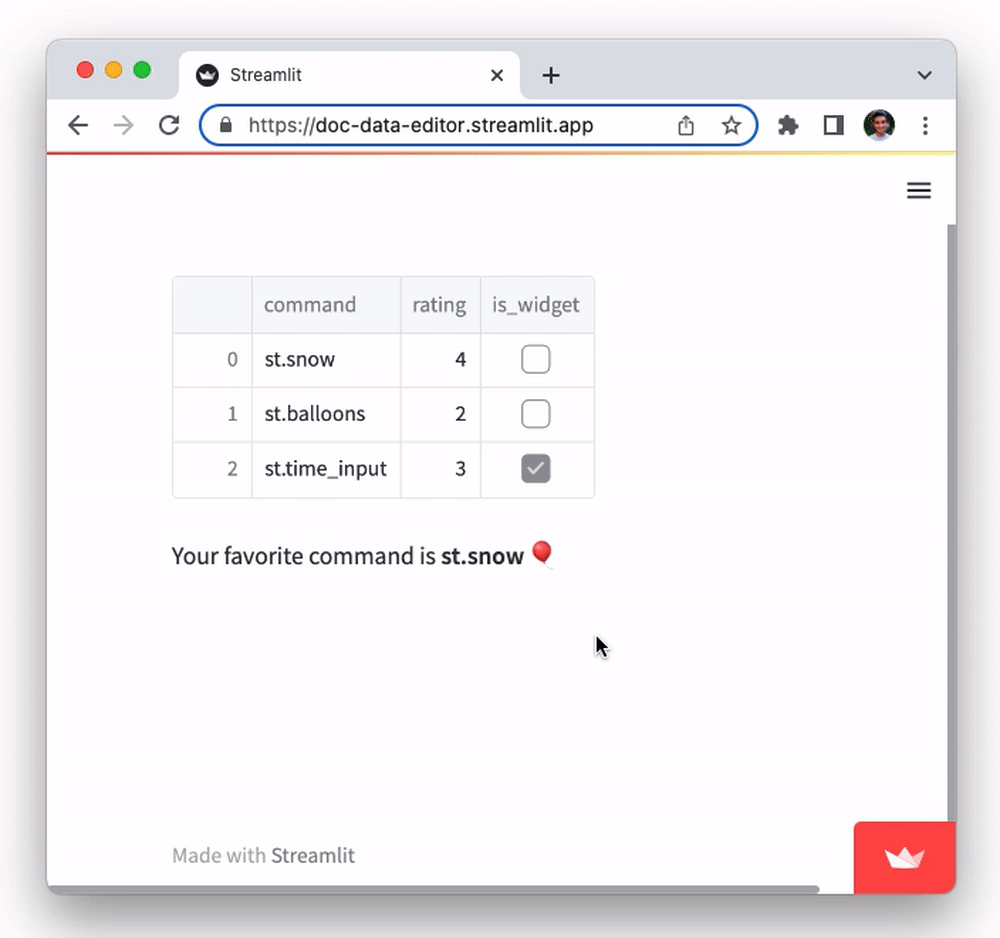
edited_df = st.data_editor(df) # 👈 An editable dataframe
favorite_command = edited_df.loc[edited_df["rating"].idxmax()]["command"]
st.markdown(f"Your favorite command is **{favorite_command}** 🎈")
Try it out by double-clicking on any cell. You'll notice you can edit all cell values. Try editing the values in the rating column and observe how the text output at the bottom changes:
st.data_editor also supports a few additional things:
- Copy and paste support from and to Excel and Google Sheets.
- Add and delete rows. You can do this by setting
num_rows= "dynamic"when callingst.data_editor. This will allow users to add and delete rows as needed. - Access edited data. Only access the individual edits instead of the entire edited data structure via session state.
- Bulk edits (similar to Excel, just drag a handle to edit neighboring cells).
- Automatic input validation, a strong data type support. e.g. There's no way to enter letters into a number cell and many other configurable input validation options. e.g. min-/max-value.
- Edit common data structures such as lists, dicts, NumPy ndarray, etc.
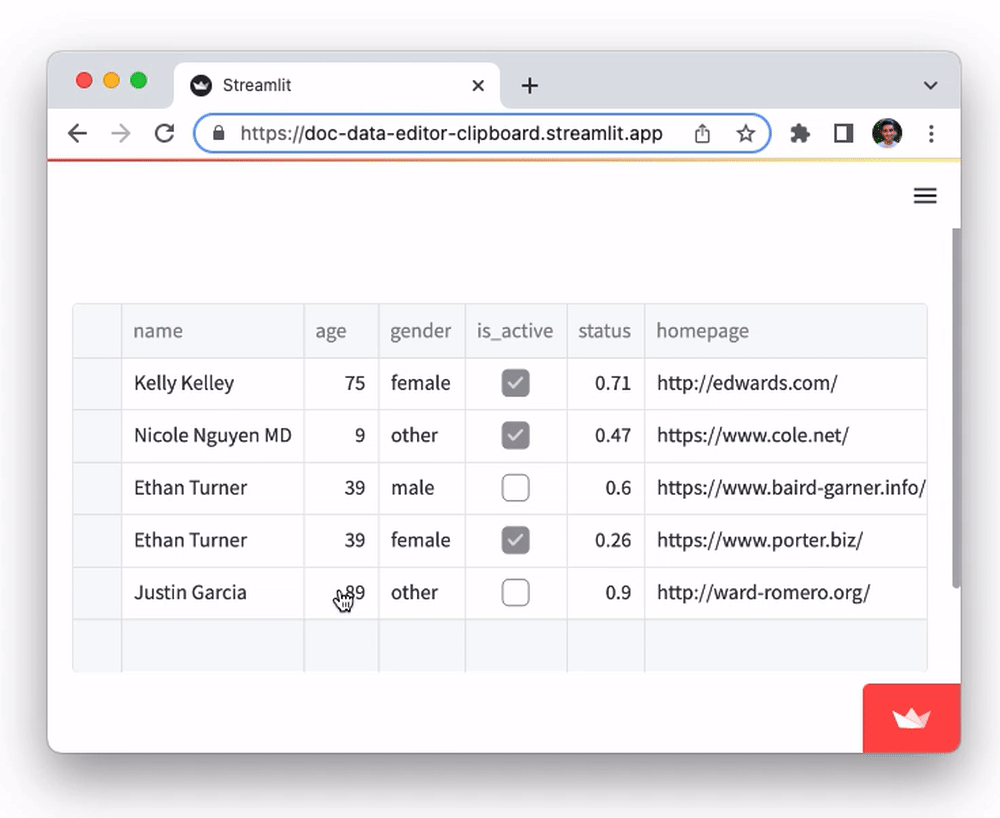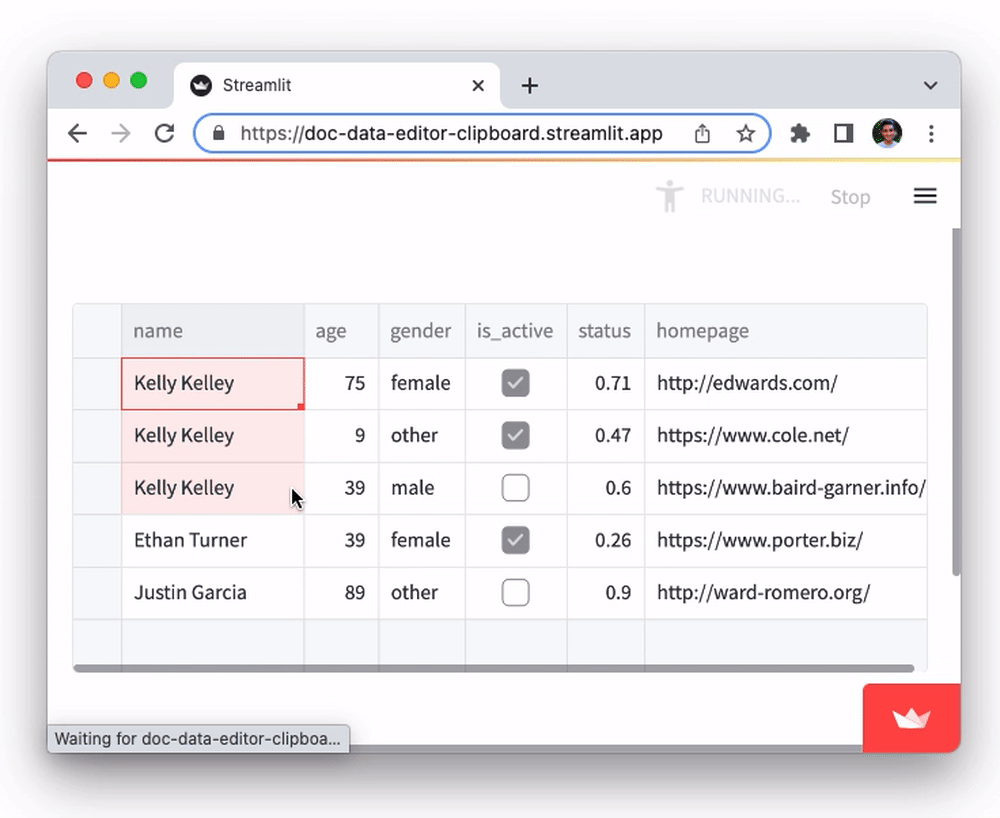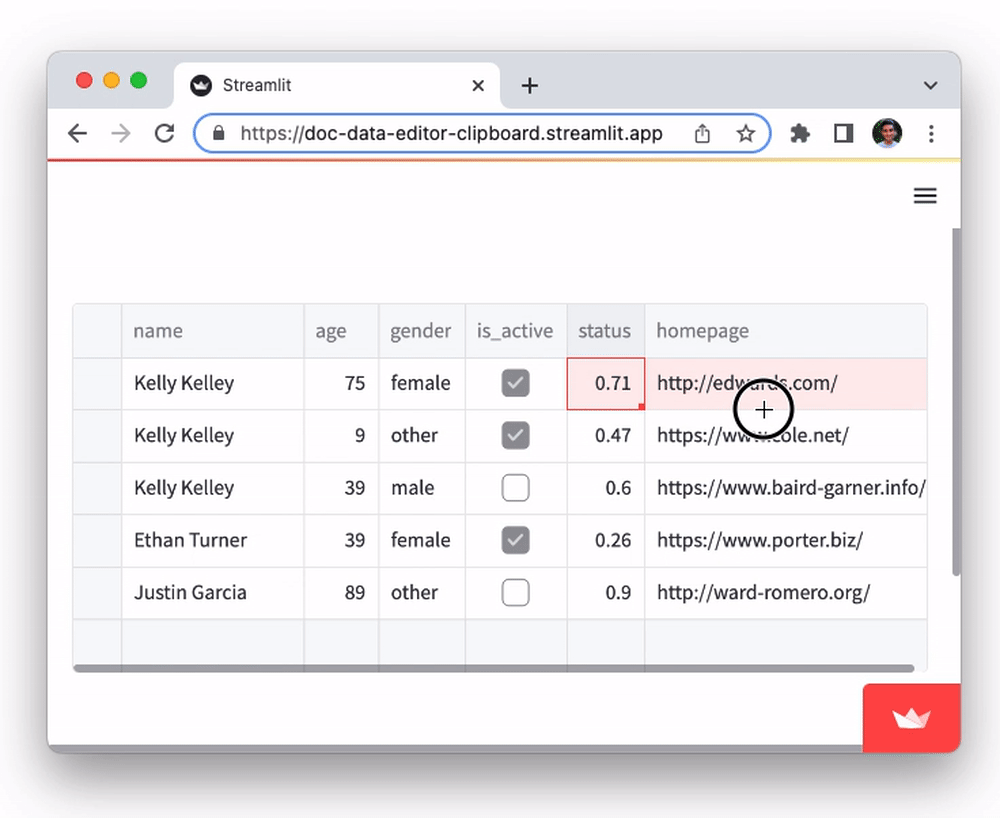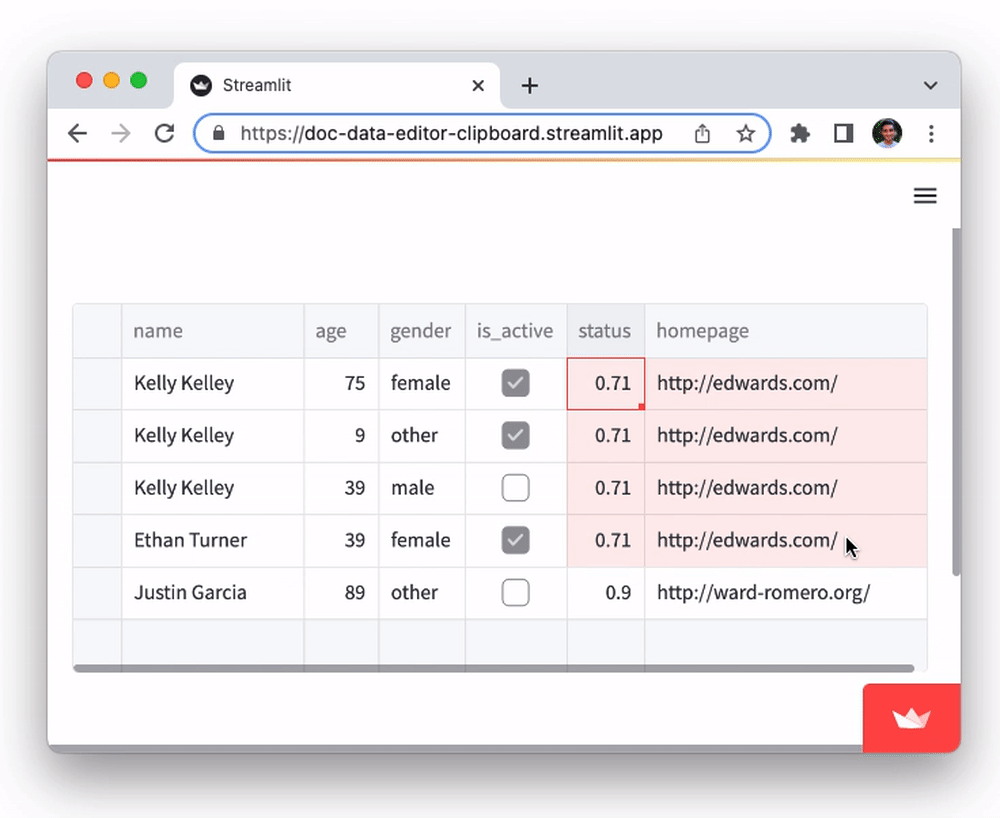
Copy and paste support
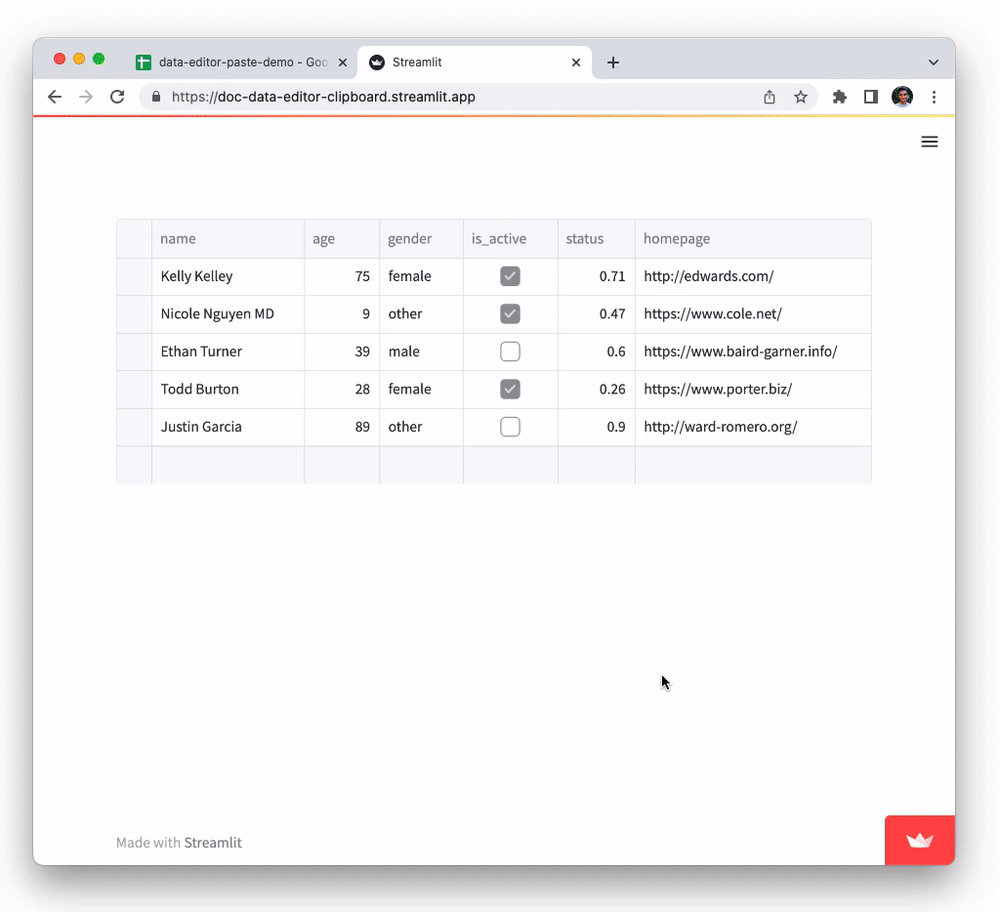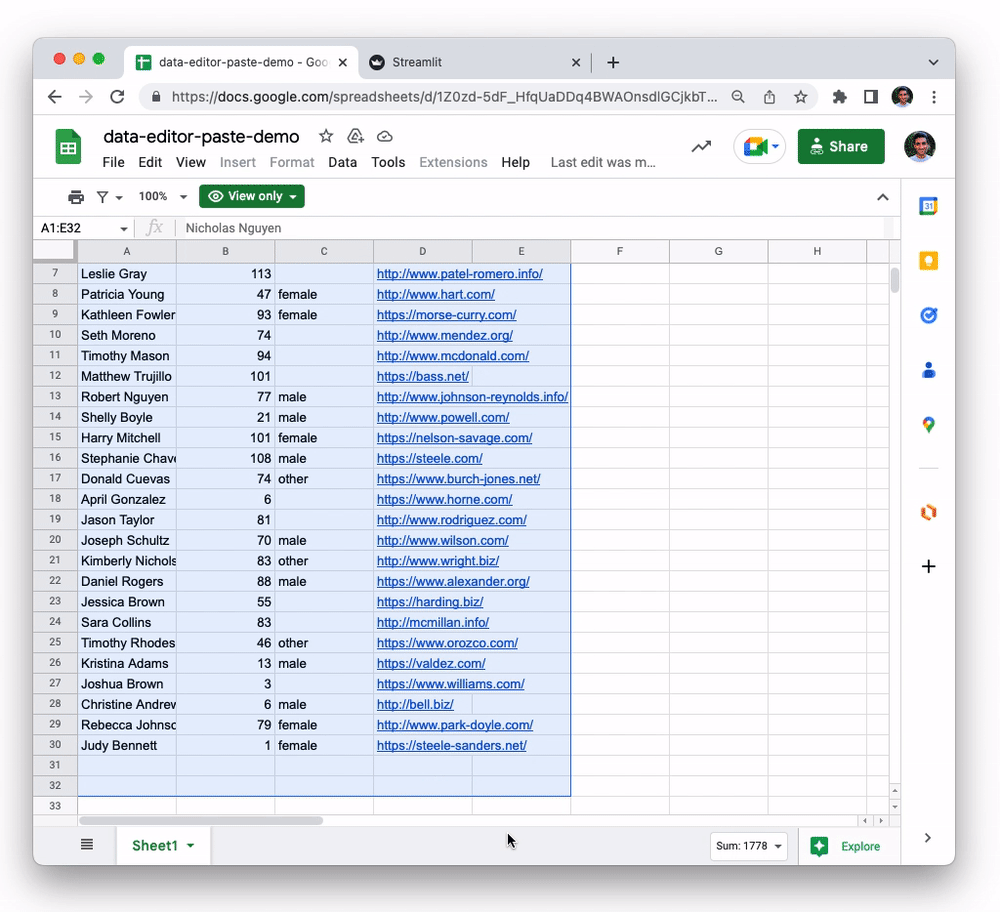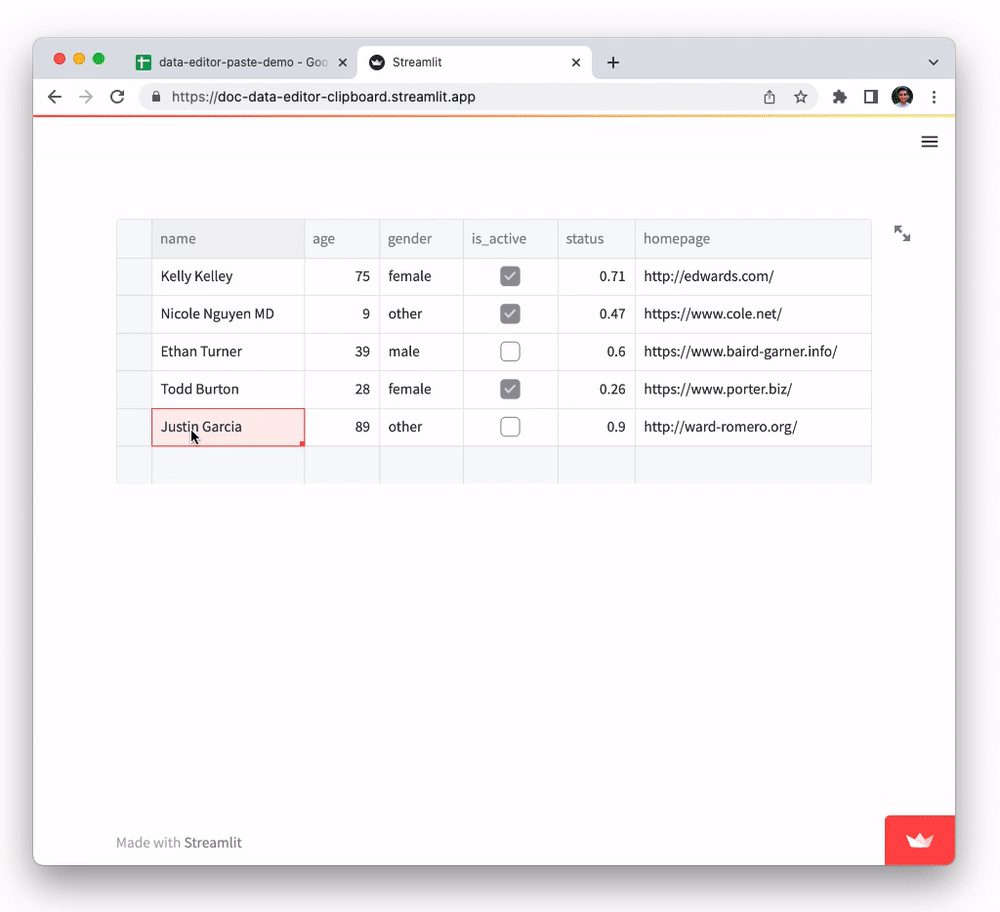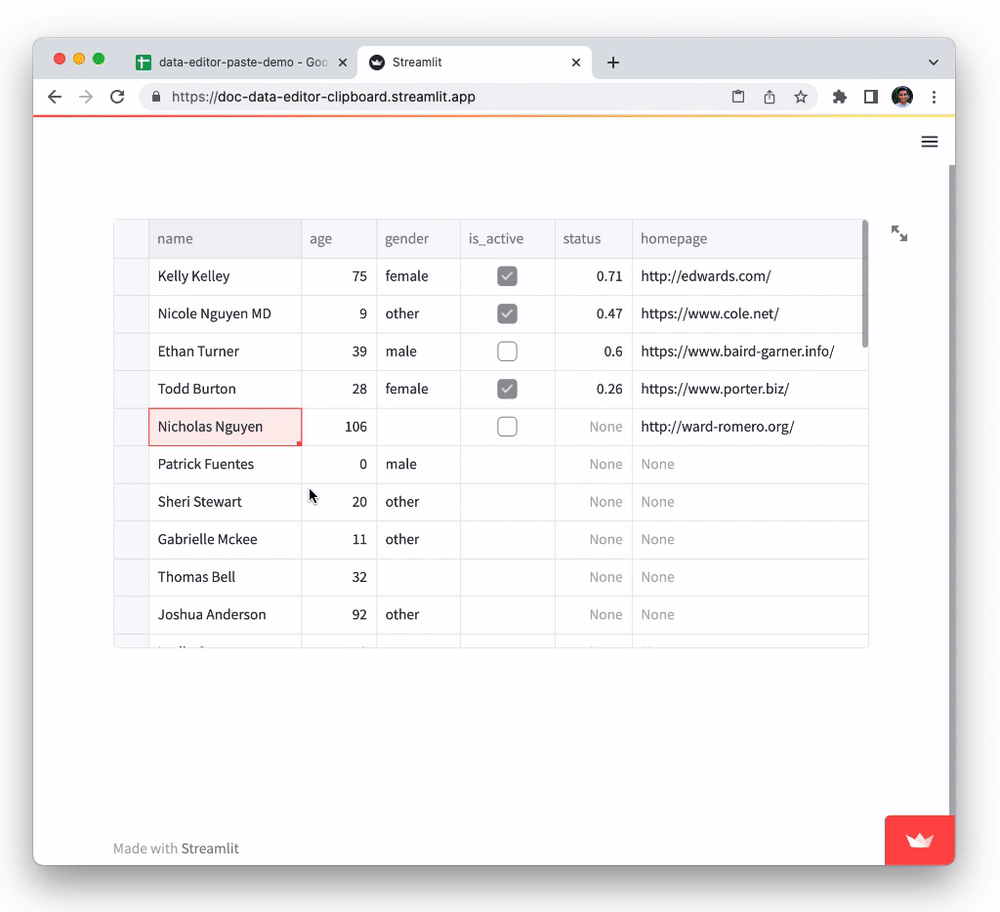
The data editor supports pasting in tabular data from Google Sheets, Excel, Notion, and many other similar tools. You can also copy-paste data between st.data_editor instances. This functionality, powered by the Clipboard API, can be a huge time saver for users who need to work with data across multiple platforms. To try it out:
- Copy data from this Google Sheets document to clipboard
- Select any cell in the
namecolumn of the table below and paste it in (viactrl/cmd + v).
Note
Every cell of the pasted data will be evaluated individually and inserted into the cells if the data is compatible with the column type. E.g., pasting in non-numerical text data into a number column will be ignored.
Did you notice that although the initial dataframe had just five rows, pasting all those rows from the spreadsheet added additional rows to the dataframe? 👀 Let's find out how that works in the next section.
Tip
If you embed your apps with iframes, you'll need to allow the iframe to access the clipboard if you want to use the copy-paste functionality. To do so, give the iframe clipboard-write and clipboard-read permissions. E.g.
<iframe allow="clipboard-write;clipboard-read;" ... src="https://your-app-url"></iframe>
As developers, ensure the app is served with a valid, trusted certificate when using TLS. If users encounter issues with copying and pasting data, direct them to check if their browser has activated clipboard access permissions for the Streamlit application, either when prompted or through the browser's site settings.
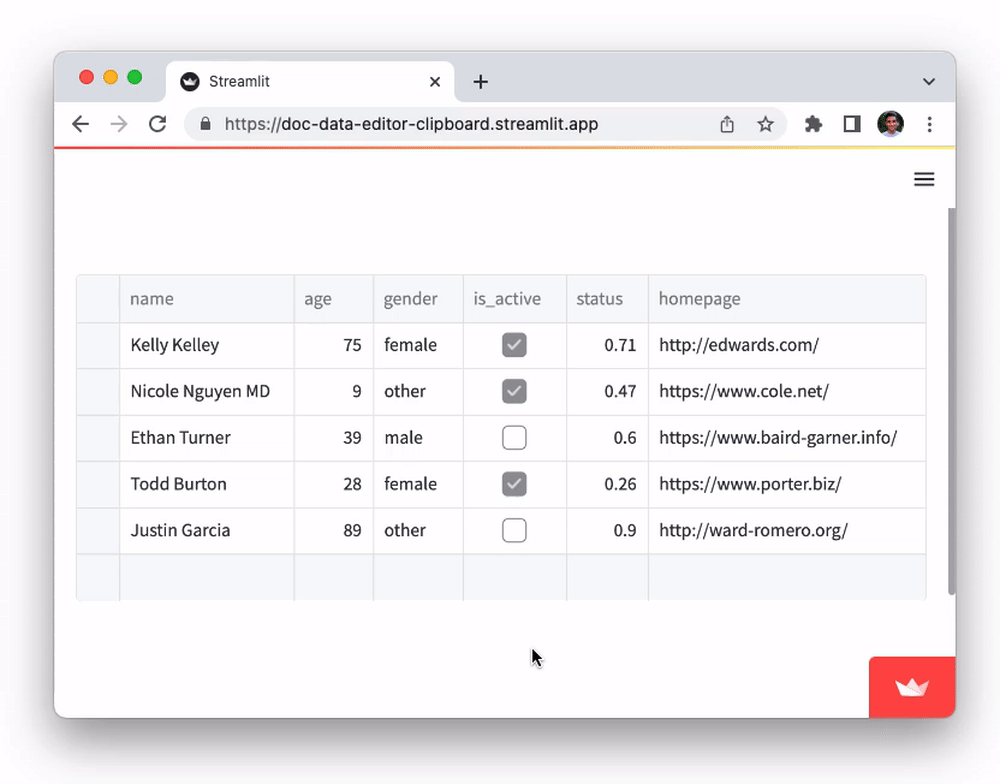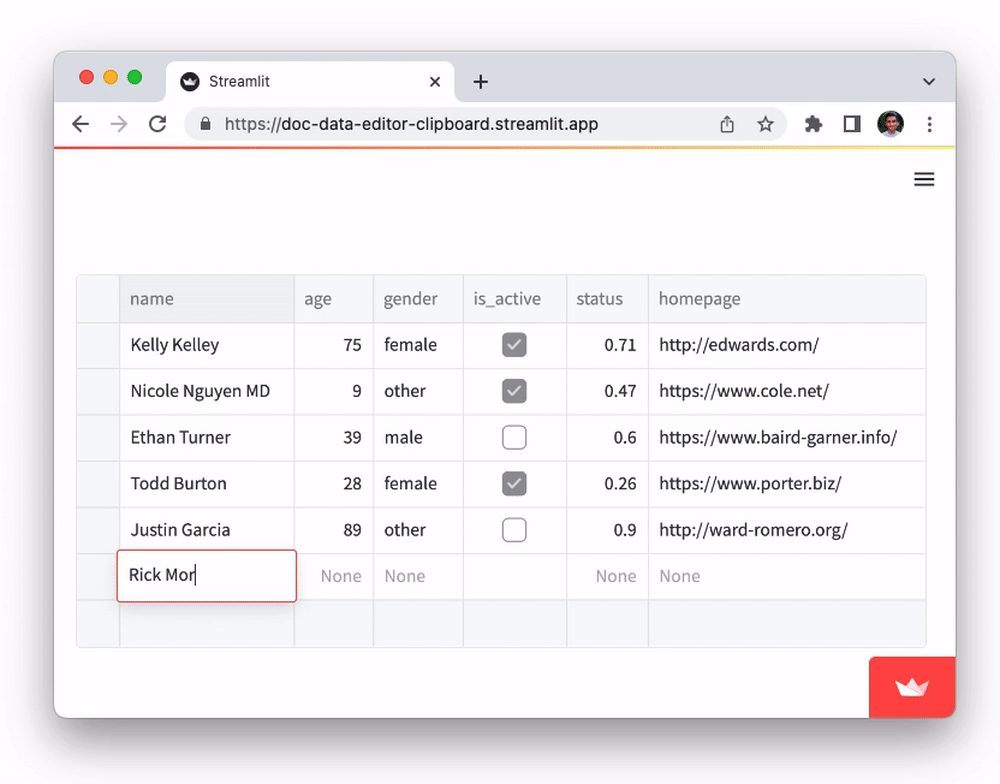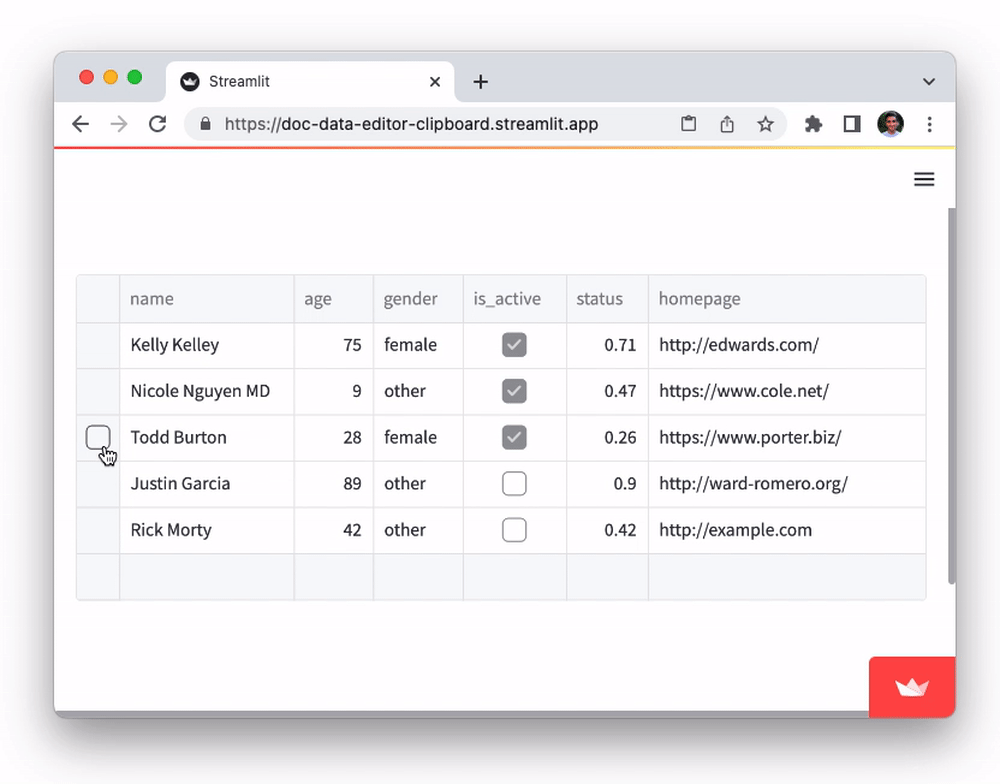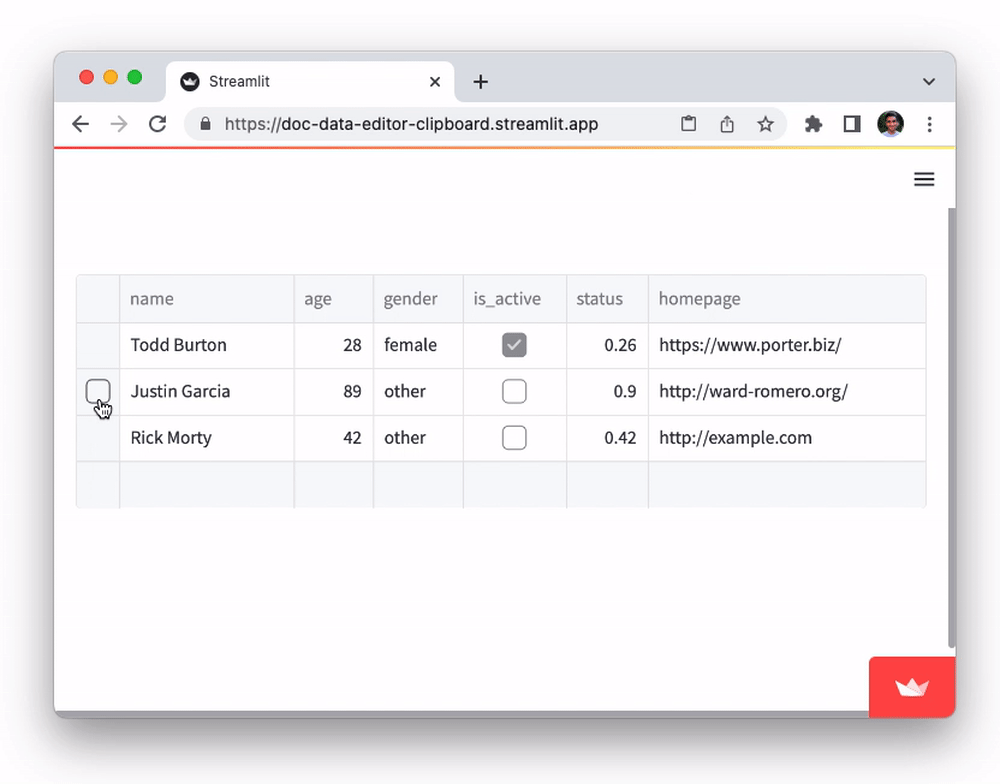
Add and delete rows
With st.data_editor, viewers can add or delete rows via the table UI. This mode can be activated by setting the num_rows parameter to "dynamic". E.g.
edited_df = st.data_editor(df, num_rows="dynamic")
- To add new rows, scroll to the bottom-most row and click on the “+" sign in any cell.
- To delete rows, select one or more rows and press the
deletekey on your keyboard.
Access edited data
Sometimes, it is more convenient to know which cells have been changed rather than getting the entire edited dataframe back. Streamlit makes this easy through the use of session state. If a key parameter is set, Streamlit will store any changes made to the dataframe in the session state.
This snippet shows how you can access changed data using session state:
st.data_editor(df, key="data_editor") # 👈 Set a key
st.write("Here's the session state:")
st.write(st.session_state["data_editor"]) # 👈 Access the edited data
In this code snippet, the key parameter is set to "data_editor". Any changes made to the data in the st.data_editor instance will be tracked by Streamlit and stored in session state under the key "data_editor".
After the data editor is created, the contents of the "data_editor" key in session state are printed to the screen using st.write(st.session_state["data_editor"]). This allows you to see the changes made to the original dataframe without having to return the entire dataframe from the data editor.
This can be useful when working with large dataframes and you only need to know which cells have changed, rather than the entire edited dataframe.
Use all we've learned so far and apply them to the above embedded app. Try editing cells, adding new rows, and deleting rows.
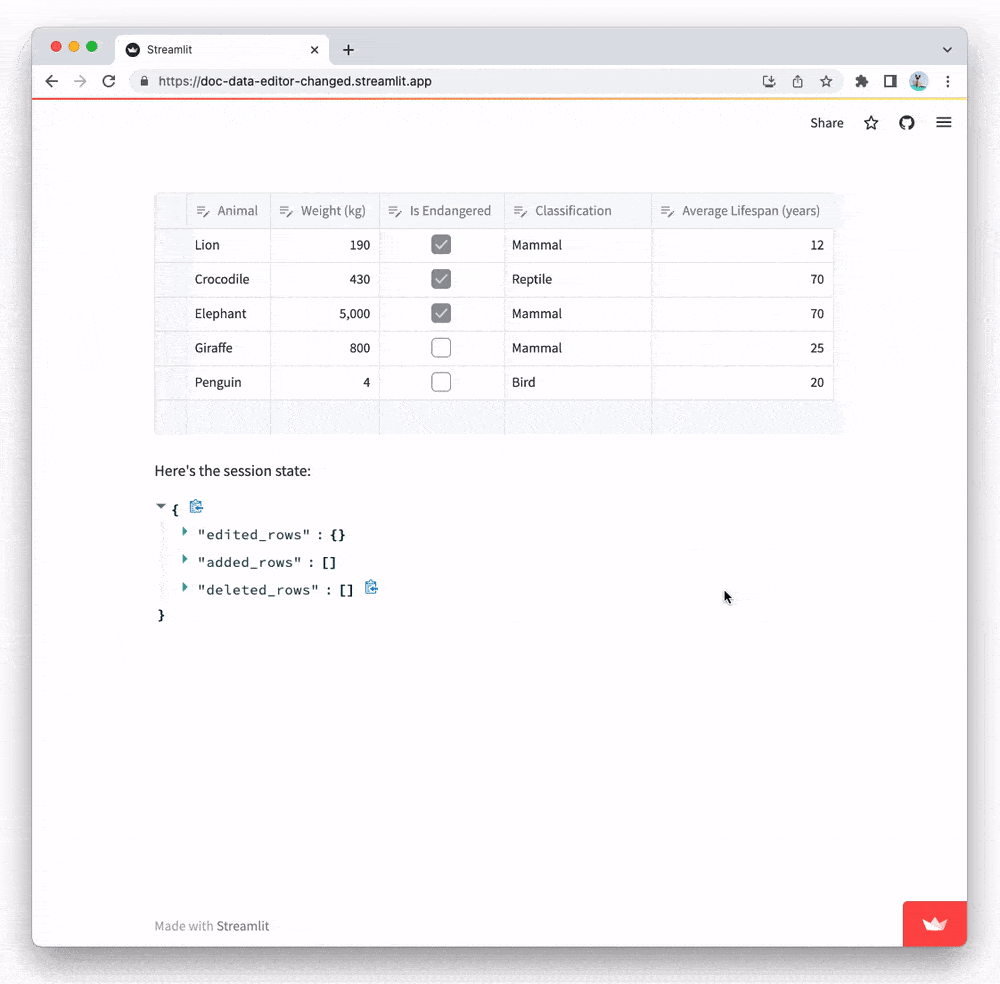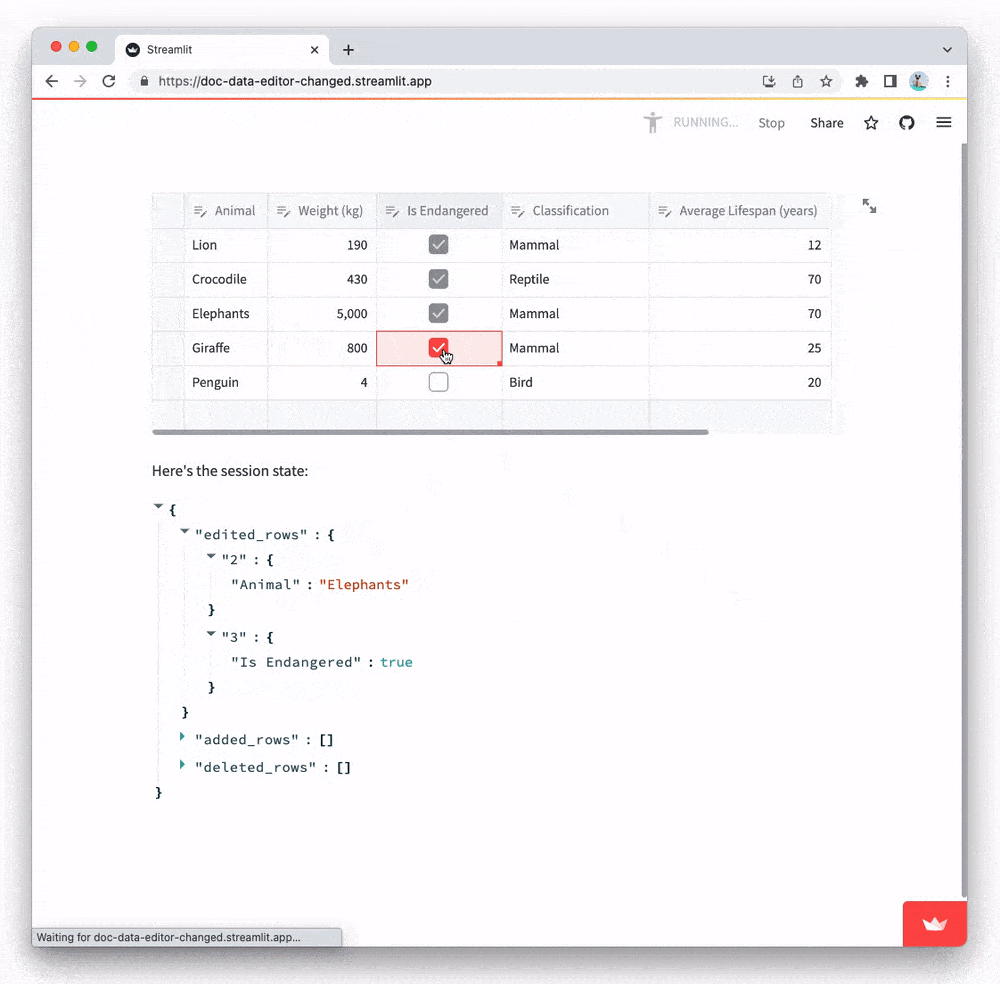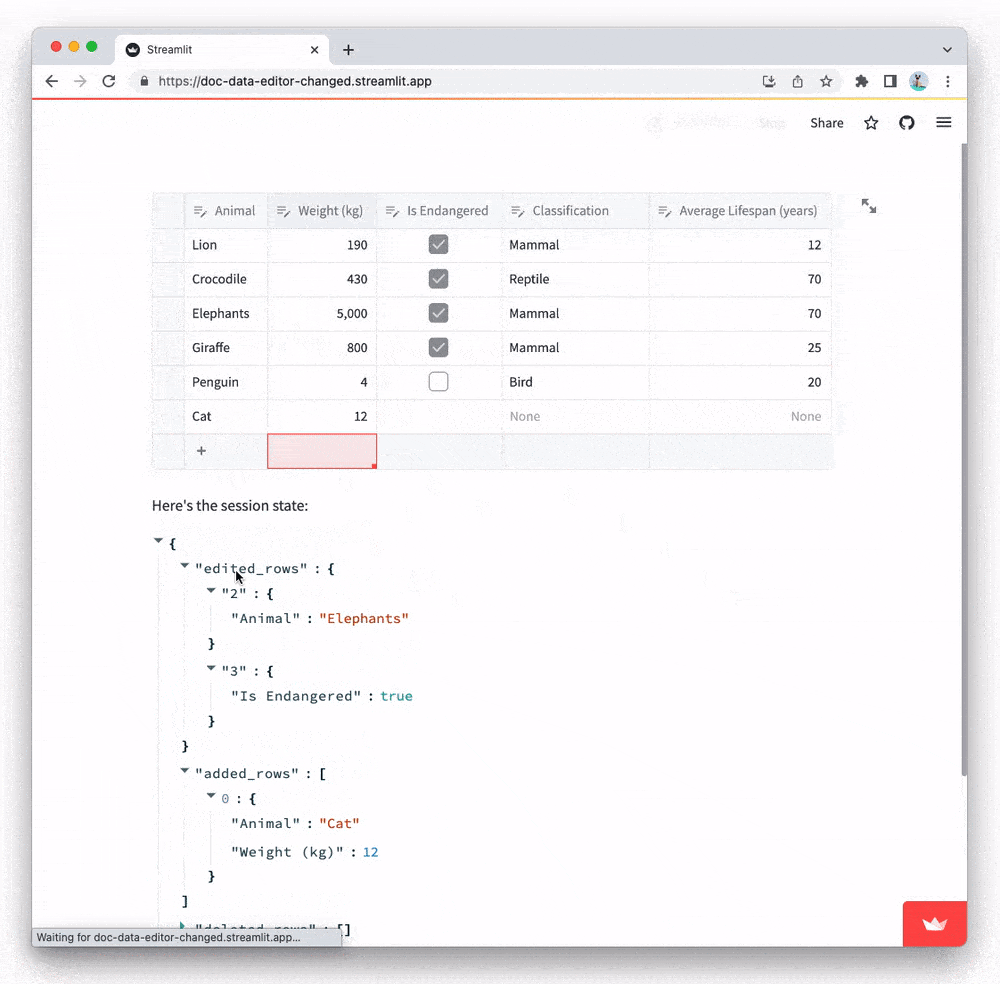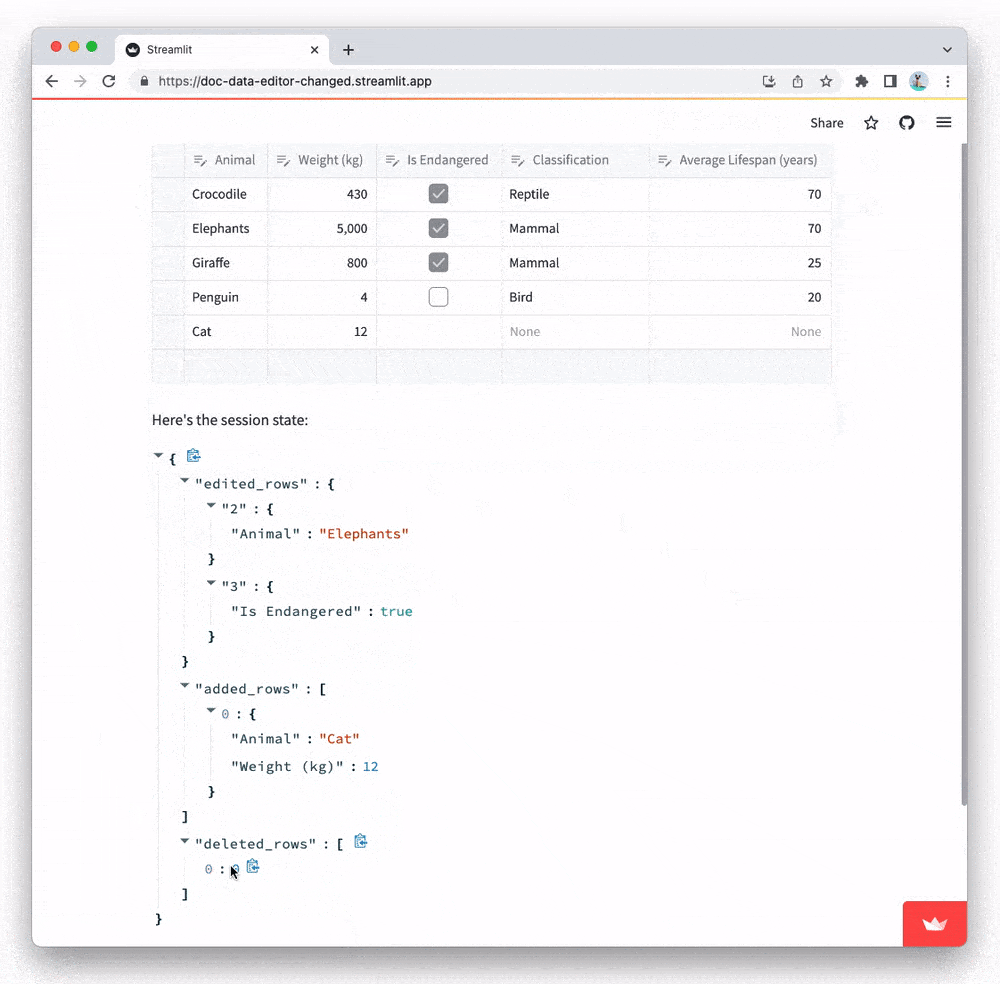
Notice how edits to the table are reflected in session state: when you make any edits, a rerun is triggered which sends the edits to the backend via st.data_editor's keyed widget state. Its widget state is a JSON object containing three properties: edited_rows, added_rows, and deleted rows:.
Warning
When going from st.experimental_data_editor to st.data_editor in 1.23.0, the data editor's representation in st.session_state was changed. The edited_cells dictionary is now called edited_rows and uses a different format ({0: {"column name": "edited value"}} instead of {"0:1": "edited value"}). You may need to adjust the code if your app uses st.experimental_data_editor in combination with st.session_state."
edited_rowsis a dictionary containing all edits. Keys are zero-based row indices and values are dictionaries that map column names to edits (e.g.{0: {"col1": ..., "col2": ...}}).added_rowsis a list of newly added rows. Each value is a dictionary with the same format as above (e.g.[{"col1": ..., "col2": ...}]).deleted_rowsis a list of row numbers that have been deleted from the table (e.g.[0, 2]).
Bulk edits
The data editor includes a feature that allows for bulk editing of cells. Similar to Excel, you can drag a handle across a selection of cells to edit their values in bulk. You can even apply commonly used keyboard shortcuts in spreadsheet software. This is useful when you need to make the same change across multiple cells, rather than editing each cell individually:
Edit common data structures
Editing doesn't just work for Pandas DataFrames! You can also edit lists, tuples, sets, dictionaries, NumPy arrays, or Snowpark & PySpark DataFrames. Most data types will be returned in their original format. But some types (e.g. Snowpark and PySpark) are converted to Pandas DataFrames. To learn about all the supported types, read the st.data_editor API.
E.g. you can easily let the user add items to a list:
edited_list = st.data_editor(["red", "green", "blue"], num_rows= "dynamic")
st.write("Here are all the colors you entered:")
st.write(edited_list)
Or numpy arrays:
import numpy as np
st.data_editor(np.array([
["st.text_area", "widget", 4.92],
["st.markdown", "element", 47.22]
]))
Or lists of records:
st.data_editor([
{"name": "st.text_area", "type": "widget"},
{"name": "st.markdown", "type": "element"},
])
Or dictionaries and many more types!
st.data_editor({
"st.text_area": "widget",
"st.markdown": "element"
})
Automatic input validation
The data editor includes automatic input validation to help prevent errors when editing cells. For example, if you have a column that contains numerical data, the input field will automatically restrict the user to only entering numerical data. This helps to prevent errors that could occur if the user were to accidentally enter a non-numerical value. Additional input validation can be configured through the Column configuration API. Keep reading below for an overview of column configuration, including validation options.
Configuring columns
You can configure the display and editing behavior of columns in st.dataframe and st.data_editor via the Column configuration API. We have developed the API to let you add images, charts, and clickable URLs in dataframe and data editor columns. Additionally, you can make individual columns editable, set columns as categorical and specify which options they can take, hide the index of the dataframe, and much more.
Column configuration includes the following column types: Text, Number, Checkbox, Selectbox, Date, Time, Datetime, List, Link, Image, Line chart, Bar chart, and Progress. There is also a generic Column option. See the embedded app below to view these different column types. Each column type is individually previewed in the Column configuration API documentation.
Format values
A format parameter is available in column configuration for Text, Date, Time, and Datetime columns. Chart-like columns can also be formatted. Line chart and Bar chart columns have a y_min and y_max parameters to set the vertical bounds. For a Progress column, you can declare the horizontal bounds with min_value and max_value.
Validate input
When specifying a column configuration, you can declare not only the data type of the column but also value restrictions. All column configuration elements allow you to make a column required with the keyword parameter required=True.
For Text and Link columns, you can specify the maximum number of characters with max_chars or use regular expressions to validate entries through validate. Numerical columns, including Number, Date, Time, and Datetime have min_value and max_value parameters. Selectbox columns have a configurable list of options.
The data type for Number columns is float by default. Passing a value of type int to any of min_value, max_value, step, or default will set the type for the column as int.
Configure an empty dataframe
You can use st.data_editor to collect tabular input from a user. When starting from an empty dataframe, default column types are text. Use column configuration to specify the data types you want to collect from users.
import streamlit as st
import pandas as pd
df = pd.DataFrame(columns=['name','age','color'])
colors = ['red', 'orange', 'yellow', 'green', 'blue', 'indigo', 'violet']
config = {
'name' : st.column_config.TextColumn('Full Name (required)', width='large', required=True),
'age' : st.column_config.NumberColumn('Age (years)', min_value=0, max_value=122),
'color' : st.column_config.SelectboxColumn('Favorite Color', options=colors)
}
result = st.data_editor(df, column_config = config, num_rows='dynamic')
if st.button('Get results'):
st.write(result)
Additional formatting options
In addition to column configuration, st.dataframe and st.data_editor have a few more parameters to customize the display of your dataframe.
hide_index: Set toTrueto hide the dataframe's index.column_order: Pass a list of column labels to specify the order of display.disabled: Pass a list of column labels to disable them from editing. This let's you avoid disabling them individually.
Handling large datasets
st.dataframe and st.data_editor have been designed to theoretically handle tables with millions of rows thanks to their highly performant implementation using the glide-data-grid library and HTML canvas. However, the maximum amount of data that an app can realistically handle will depend on several other factors, including:
- The maximum size of WebSocket messages: Streamlit's WebSocket messages are configurable via the
server.maxMessageSizeconfig option, which limits the amount of data that can be transferred via the WebSocket connection at once. - The server memory: The amount of data that your app can handle will also depend on the amount of memory available on your server. If the server's memory is exceeded, the app may become slow or unresponsive.
- The user's browser memory: Since all the data needs to be transferred to the user's browser for rendering, the amount of memory available on the user's device can also affect the app's performance. If the browser's memory is exceeded, it may crash or become unresponsive.
In addition to these factors, a slow network connection can also significantly slow down apps that handle large datasets.
When handling large datasets with more than 150,000 rows, Streamlit applies additional optimizations and disables column sorting. This can help to reduce the amount of data that needs to be processed at once and improve the app's performance.
Limitations
While Streamlit's data editing capabilities offer a lot of functionality, there are some limitations to be aware of:
- Editing is enabled for a limited set of column types (TextColumn, NumberColumn, LinkColumn, CheckboxColumn, SelectboxColumn, DateColumn, TimeColumn, and DatetimeColumn). We are actively working on supporting editing for other column types as well, such as images, lists, and charts.
- Editing of Pandas DataFrames only supports the following index types:
RangeIndex, (string)Index,Float64Index,Int64Index, andUInt64Index. - Some actions like deleting rows or searching data can only be triggered via keyboard hotkeys.
We are working to fix the above limitations in future releases, so keep an eye out for updates.
Still have questions?
Our forums are full of helpful information and Streamlit experts.